any-llm
综合介绍
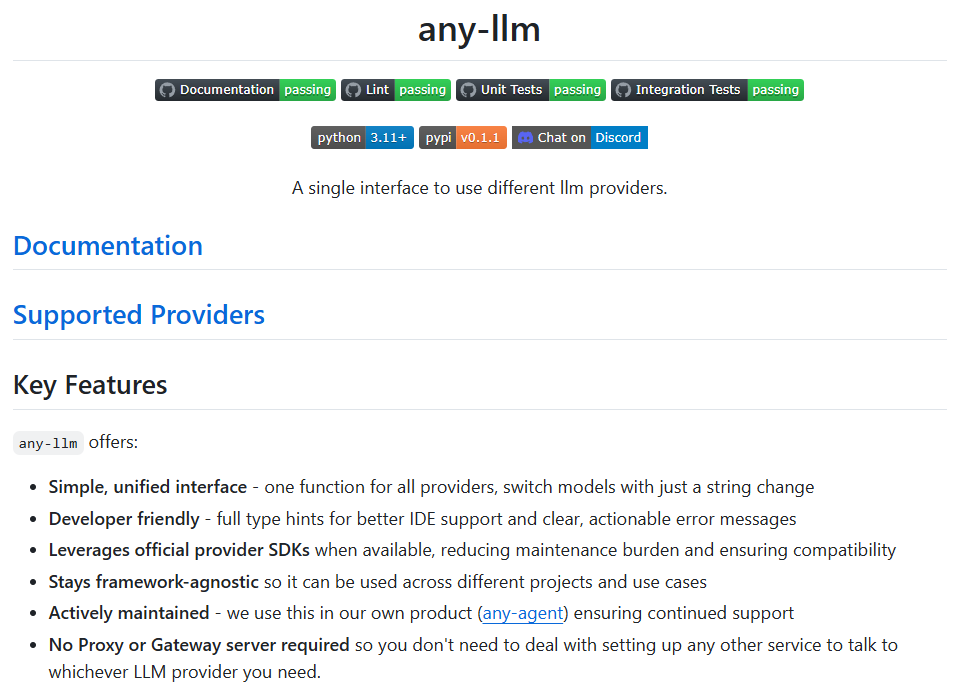
any-llm 是一个由 Mozilla AI 团队开发的 Python 库。它为开发者提供了一个统一且简单的编程接口,用来调用市面上各种不同的大语言模型(LLM)。在当前的AI应用开发中,开发者常常需要面对来自不同服务商(如 OpenAI、Anthropic、Google 等)的多种模型,而这些模型的接口各有差异,导致切换和管理变得非常复杂。any-llm 的目标就是解决这个问题,它通过封装各个官方提供的软件开发工具包(SDK),让开发者可以用同一套代码与超过20种不同的LLM服务进行交互。开发者只需要更改一个模型标识字符串,就能轻松地在不同模型之间切换。这种设计不仅简化了开发流程,还因为直接利用官方SDK,保证了功能的稳定性和兼容性,避免了重复造轮子可能带来的问题。any-llm 本身不需要部署一个额外的代理或网关服务,可以直接在项目中以库的形式被调用,让整个开发过程更加轻便和直接。
功能列表
- 统一接口: 提供一个名为
completion的核心函数,用于调用所有支持的LLM服务商。 - 轻松切换模型: 仅需修改
model参数中的字符串(格式为服务商ID/模型ID),即可无缝切换到不同的大语言模型。 - 广泛的服务商支持: 支持超过20家LLM服务商,包括 OpenAI、Anthropic、Google、Mistral、AWS Bedrock 和本地模型工具 Ollama 等主流平台。
- 流式响应 (Streaming): 支持处理模型的流式输出,可以一块一块地接收和处理模型生成的文本,适合用于开发实时聊天等应用。
- 利用官方SDK: 优先使用并封装各个服务商发布的官方Python SDK,确保了API调用的稳定、可靠和兼容性,并能及时获得官方更新。
- 无需额外服务: 作为一个Python库直接集成在项目中,不需要开发者部署和维护任何中间代理或网关服务器。
- 对开发者友好: 具备完整的类型提示(Type Hints),在VS Code等集成开发环境中能提供良好的代码补全和错误检查。同时,错误信息清晰明确,便于快速定位问题。
- 框架无关:
any-llm保持独立,不依赖于任何特定的AI代理框架,可以灵活地集成到各种不同的项目中。
使用帮助
any-llm 的设计目标是让开发者能够以最简单的方式在项目中集成和切换不同的大语言模型。下面将详细介绍其安装、配置和具体使用方法。
1. 环境要求
在开始之前,请确保你的开发环境满足以下要求:
- Python 版本: 3.11 或更高版本。
2. 安装
any-llm 的安装非常灵活,你可以只安装你需要的特定服务商支持包,也可以一次性安装所有支持包。这种按需安装的方式可以避免下载和安装不必要的依赖库,保持你的项目环境整洁。
安装命令的基本格式是 pip install 'any-llm-sdk[provider1,provider2,...]'。
示例1:只安装 Mistral 和 Ollama 的支持如果你计划只使用 Mistral 的云端模型和 Ollama 驱动的本地模型,可以执行以下命令:
pip install 'any-llm-sdk[mistral,ollama]'
示例2:安装所有支持的服务商如果你希望能够灵活地测试和切换所有 any-llm 支持的模型,可以使用 all 选项:
pip install 'any-llm-sdk[all]'
3. 配置API密钥
要与云端的大语言模型服务商通信,你需要提供相应的API密钥。any-llm 支持两种配置方式:环境变量和直接传参。
方式一:使用环境变量(推荐)这是最常用也是官方推荐的方式,因为它可以将密钥与代码分离开。你需要为每个服务商设置对应的环境变量。
例如,如果你要使用 Mistral 的服务,需要设置 MISTRAL_API_KEY:
export MISTRAL_API_KEY="你的Mistral_API密钥"
同理,如果要使用 OpenAI 的服务,则设置 OPENAI_API_KEY:
export OPENAI_API_KEY="你的OpenAI_API密钥"
程序在运行时会自动读取这些环境变量。
方式二:在代码中直接传入密钥如果你不想或不能设置环境变量,也可以在调用 completion 函数时,通过 api_key 参数直接传入密钥。
from any_llm import completion
response = completion(
model="mistral/mistral-small-latest",
messages=[{"role": "user", "content": "你好,请问你是谁?"}],
api_key="你的Mistral_API密钥" # 直接传入密钥
)
这种方式比较直接,但不利于密钥的保密和管理,请谨慎在生产环境中使用。
4. 基本用法:发送请求并获取回复
any-llm 的核心是 completion 函数,所有的模型调用都通过它来完成。
主要步骤:
- 从
any_llm库中导入completion函数。 - 准备一个消息列表
messages,其格式与 OpenAI 的 API 标准一致,每个消息都是一个字典,包含role(角色,如 "user")和content(内容)。 - 调用
completion函数,并传入model和messages参数。model参数的格式是"provider_id/model_id"。例如,"openai/gpt-4o"表示使用 OpenAI 提供的gpt-4o模型。
代码示例:
import os
from any_llm import completion
# 确保已经通过环境变量设置了API密钥
# 这里以 Mistral 为例
assert os.environ.get('MISTRAL_API_KEY'), "请设置 MISTRAL_API_KEY 环境变量"
# 准备发送给模型的消息
messages = [
{"role": "user", "content": "你好,请用中文介绍一下你自己。"}
]
# 调用 completion 函数
response = completion(
model="mistral/mistral-small-latest", # 指定服务商和模型
messages=messages
)
# 打印模型返回的完整回复内容
print(response.choices[0].message.content)```
**切换模型:**
如果你想换用 Anthropic 的 Claude 3 Sonnet 模型,只需要将 `model` 参数从 `"mistral/mistral-small-latest"` 改为 `"anthropic/claude-3-sonnet-20240229"`,并确保设置了 `ANTHROPIC_API_KEY` 环境变量即可,其他代码完全不用修改。
### **5. 高级用法:处理流式响应**
对于聊天机器人或需要实时显示结果的应用场景,一次性等待模型生成全部回复的体验不佳。`any-llm` 支持流式响应,可以让模型在生成文本的同时,将一小块一小块的结果实时返回给客户端。
要启用流式响应,只需要在调用 `completion` 函数时增加一个参数 `stream=True`。
**主要步骤:**
1. 在 `completion` 函数调用中设置 `stream=True`。
2. 此时,函数的返回值将不再是完整的响应对象,而是一个生成器(generator)。
3. 你需要使用 `for` 循环来遍历这个生成器,每次循环处理一小块返回的数据。
**代码示例:**
```python
import os
from any_llm import completion
# 确保API密钥已设置
assert os.environ.get('OPENAI_API_KEY'), "请设置 OPENAI_API_KEY 环境变量"
messages = [
{"role": "user", "content": "请写一个关于太空探索的短故事。"}
]
# 调用 completion 函数并启用流式传输
response_stream = completion(
model="openai/gpt-4o",
messages=messages,
stream=True # 启用流式响应
)
print("模型正在生成故事:")
# 遍历返回的流式响应生成器
for chunk in response_stream:
# 提取每一块中的文本内容
content_chunk = chunk.choices[0].delta.content
if content_chunk:
# 实时打印输出,end=""确保内容连续显示
print(content_chunk, end="", flush=True)
print("\n故事生成完毕。")
在这个例子中,模型生成的故事会一个词一个词或一个句子一个句子地显示在屏幕上,而不是等整个故事写完后才一次性显示。这极大地提升了用户体验。
应用场景
- 构建多模型AI应用如果一个应用需要根据用户请求的类型或成本预算,动态选择最合适的LLM来处理任务。例如,简单的问答可以使用成本较低的 Mistral 模型,而复杂的逻辑推理则切换到能力更强的 GPT-4o 或 Claude 3 Opus 模型。
any-llm让这种切换只需要改变一个字符串即可实现。 - LLM性能评测平台研究人员和开发者需要一个标准化的环境来评测和比较不同LLM在特定任务上的表现。使用
any-llm,可以编写一次评测脚本,然后通过循环传入不同的模型ID,将同一组测试集发送给多个模型,并统一收集和分析它们的输出结果。 - 快速原型开发与实验在探索新的AI产品想法时,开发者可能不确定哪个LLM最适合。
any-llm提供了一个“即插即用”的实验平台,让开发者可以快速尝试多种模型,而无需为每个模型编写和调试特定的API调用代码,从而加速了产品原型的验证过程。 - 为AI智能体(Agent)提供后端支持
any-llm本身就诞生于 Mozilla AI 的any-agent项目中。它可以作为一个可靠的组件,为需要与外部世界(通过LLM)交互的AI智能体提供思考和语言能力。开发者可以专注于智能体的逻辑设计,而将与LLM的通信交给any-llm处理。
QA
any-llm和 LiteLLM 有什么主要区别?最核心的区别在于实现方式。any-llm优先使用各个LLM服务商官方发布的Python SDK来进行API调用,而LiteLLM则自己重新实现了一套兼容各个服务商API的HTTP请求逻辑。any-llm的方法可以更好地保证与官方服务的兼容性、稳定性和对新功能的支持,同时减少了自身的维护负担。- 如何知道
provider_id和model_id应该填什么?provider_id是any-llm定义的服务商标识,例如openai、anthropic、mistral等。model_id则是对应服务商官方定义的模型名称,例如gpt-4o、claude-3-opus-20240229等。你需要查阅具体LLM服务商的官方文档来获取它们提供的可用模型ID列表。 - 是否支持在本地运行的模型?是。
any-llm通过ollama支持包,可以与在本地运行的Ollama服务进行交互。你只需安装Ollama,下载你需要的模型(如Llama 3, Phi-3等),然后在any-llm中将model参数指定为"ollama/模型名称"即可,例如"ollama/llama3"。 - 这个项目是否会持续维护?会。根据官方介绍,
any-llm是Mozilla AI团队内部产品any-agent的核心依赖组件之一 ,并且正在被实际使用,因此它会得到持续的维护和更新以确保其在生产环境中的稳定性。